Transformer的原理
Google Tensor2Tensor系统是一套十分强大的深度学习系统,在多个任务上的表现非常抢眼。尤其在机器翻译问题上,单模型的表现就可以超过之前方法的集成模型。这一套系统的模型结构、训练和优化技巧等,可以被利用到公司的产品线上,直接转化成生产力。
Tensor2Tensor(T2T)是Google Brain Team在Github上开源出来的一套基于TensorFlow的深度学习系统。该系统最初是希望完全使用Attention方法来建模序列到序列(Sequence-to-Sequence,Seq2Seq)的问题,对应于《Attention Is All You Need》这篇论文。该项工作有一个有意思的名字叫“Transformer”。随着系统的不断扩展,T2T支持的功能变得越来越多,目前可以建模的问题包括:图像分类,语言模型、情感分析、语音识别、文本摘要,机器翻译。T2T在很多任务上的表现很好,并且模型收敛比较快,在TF平台上的工程化代码实现的也非常好,是一个十分值得使用和学习的系统。
如果是从工程应用的角度出发,想快速的上手使用T2T系统,只需要对模型有一些初步的了解,阅读一下workthrough文档,很快就能做模型训练和数据解码了。这就是该系统想要达到的目的,即降低深度学习模型的使用门槛。系统对数据处理、模型、超参、计算设备都进行了较高的封装,在使用的时候只需要给到数据路径、指定要使用的模型和超参、说明计算设备就可以将系统运行起来了。
序列到序列(Sequence-to-Sequence)是自然语言处理中的一个常见任务,主要用来做泛文本生成的任务,像机器翻译、文本摘要、歌词/故事生成、对话机器人等。最具有代表性的一个任务就是机器翻译(Machine Translation),将一种语言的序列映射到另一个语言的序列。例如,在汉-英机器翻译任务中,模型要将一个汉语句子(词序列)转化成一个英语句子(词序列)。
目前Encoder-Decoder框架是解决序列到序列问题的一个主流模型。模型使用Encoder对source sequence进行压缩表示,使用Decoder基于源端的压缩表示生成target sequence。该结构的好处是可以实现两个sequence之间end-to-end方式的建模,模型中所有的参数变量统一到一个目标函数下进行训练,模型表现较好。图1展示了Encoder-Decoder模型的结构,从底向上是一个机器翻译的过程。
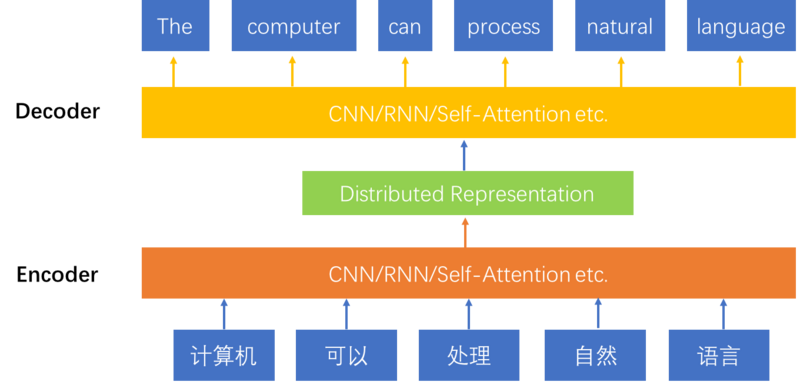
Encoder和Decoder可以选用不同结构的Neural Network,比如RNN、CNN。RNN的工作方式是对序列根据时间步,依次进行压缩表示。使用RNN的时候,一般会使用双向的RNN结构。具体方式是使用一个RNN对序列中的元素进行从左往右的压缩表示,另一个RNN对序列进行从右向左的压缩表示。两种表示被联合起来使用,作为最终序列的分布式表示。使用CNN结构的时候,一般使用多层的结构,来实现序列局部表示到全局表示的过程。使用RNN建模句子可以看做是一种时间序列的观点,使用CNN建模句子可以看做一种结构化的观点。使用RNN结构的序列到序列模型主要包括RNNSearch、GNMT等,使用CNN结构的序列到序列模型主要有ConvS2S等。
BERT的原理
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
BERT中使用的编码器是一种基于注意力的自然语言处理(NLP)架构,它在一年前的Attention Is All You Need一文中引入。
自今年早些时候ULMFiT发布以来,转学习已迅速成为NLP最先进成果的标准 。之后,通过将变压器与转移学习相结合,取得了显着的进步。 这种组合的两个标志性例子是OpenAI的GPT和Google AI的BERT。
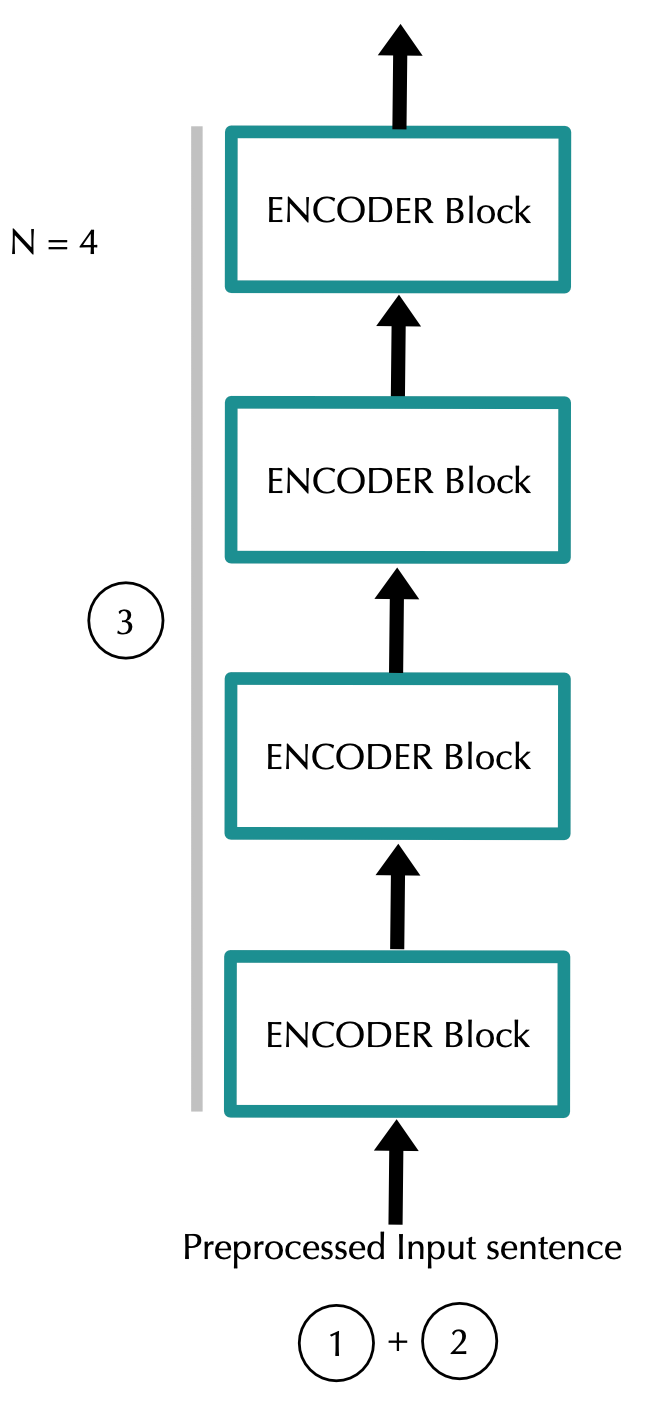
为了解释这种架构,我们将采用一般到具体的方法。我们将通过查看架构中的信息流开始,我们将潜入输入和输出的编码器作为文件中提出。接下来,我们将查看每个编码器块并了解如何使用多头注意。
信息流
通过架构的数据流如下:
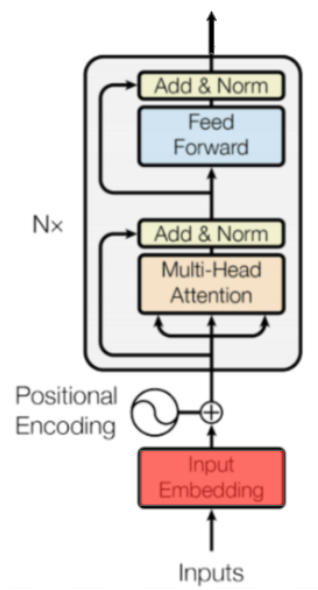
该模型将每个标记表示为emb_dim大小的向量。对于每个输入令牌使用一个嵌入向量,我们有一个特定输入序列的维度矩阵(input_length)x(emb_dim)。
然后它添加位置信息(位置编码)。此步骤返回维度矩阵(input_length)x(emb_dim),就像上一步骤一样。
数据通过N个编码器块。在此之后,我们获得尺寸矩阵(input_length)x(emb_dim)。
利用预训练的BERT模型将句子转换为句向量,进行文本分类
参考
transformer github实现:GitHub - Kyubyong/transformer: A TensorFlow Implem…
transformer pytorch分步实现:The Annotated Transformer
搞懂Transformer结构,看这篇PyTorch实现就够了:搞懂Transformer结构,看这篇PyTorch实现就够了! - TinyMind -专注人工智…
“变形金刚”为何强大:从模型到代码全面解析Google Tensor2Tensor系统:“变形金刚”为何强大:从模型到代码全面解析Google Tensor2Tensor系统 - 腾讯云技…
bert理论:
bert系列1:https://medium.com/dissecting-bert/dissecting-bert-part-1-d3c3d495cdb3
bert系列2:https://medium.com/dissecting-bert/dissecting-bert-part2-335ff2ed9c73
bert系列3:https://medium.com/dissecting-bert/dissecting-bert-appendix-the-decoder-3b86f66b0e5f
5 分钟入门 Google 最强NLP模型:BERT:5 分钟入门 Google 最强NLP模型:BERT - 简书
BERT – State of the Art Language Model for NLP:BERT – State of the Art Language Model for NLP | L…
google开源代码:GitHub - google-research/bert: TensorFlow code and…
bert实践:
干货 BERT fine-tune 终极实践教程:干货 | BERT fine-tune 终极实践教程 - 简书
小数据福音!BERT在极小数据下带来显著提升的开源实现:小数据福音!BERT在极小数据下带来显著提升的开源实现
BERT实战(源码分析+踩坑):BERT实战(源码分析 踩坑) - 知乎
