
任务
建立模型通过长文本数据正文(article),预测文本对应的类别(class)
数据
注 : 报名参赛或加入队伍后,可获取数据下载权限。
数据包含 2 个 csv 文件:
train_set.csv:此数据集用于训练模型,每一行对应一篇文章。
文章分别在“字”和“词”的级别上做了脱敏处理。
共有四列:
- 第一列是文章的索引(id),
- 第二列是文章正文在“字”级别上的表示,即字符相隔正文(article);
- 第三列是在“词”级别上的表示,即词语相隔正文(word_seg);
- 第四列是这篇文章的标注(class)。
注:每一个数字对应一个“字”,或“词”,或“标点符号”。“字”的编号与“词”的编号是独立的!
test_set.csv:此数据用于测试。
数据格式同 train_set.csv,但不包含 class。
注:test_set与train_test中文章id的编号是独立的。 友情提示:请不要尝试用excel打开这些文件!由于一篇文章太长,excel可能无法完整地读入某一行!
评分标准
评分算法
binary-classification
采用各个品类F1指标的算术平均值,它是 Precision 和 Recall 的调和平均数。
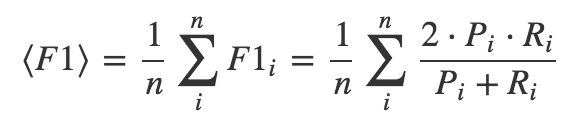
其中,Pi 是表示第 i 个种类对应的 Precision, Ri 是表示第 i 个种类对应 Recall。 AB 榜的划分方式和比例:
【1】评分采用AB榜形式,提交文件必须包含测试集中所有用户的预测值。排行榜显示A榜成绩,竞赛结束后2小时切换成B榜单。B榜成绩以选定的两次提交或者默认的最后两次提交的最高分为准,最终比赛成绩以B榜单为准。
【2】此题目的AB榜是随机划分,A榜数据占50%,B榜使用全量测试集,即占100%。
挑战赛任务背景
文本分类
- 这个比赛的任务就是文本分类,是自然语言处理 (NLP) 领域里一项 最最基本的任务。
- 但这个任务的难点就是在于,文本的长度非常长, 大约3000个词,一般任务也就300词。
- 而文本的长度过长对文本的 智能解析带来了很多挑战。
概念
- 字
- 词
- 中文分词
用传统的监督学习模型对一段文 本进行分类的基本过程
这里提前假设:
已经有了一个学习的机器学习模型 f,供你使用
注:函数输出的类别是我们事先人为约定好,比如我让数字4代表政治类, 数字3代表科技类,…
比赛数据
训练数据集
测试数据集
求解问题的本质
求一个数学函数(又可称为机器学习模型):
使模型预测能力更强
哪些机器学习算法
- 传统的监督学习算法(西瓜书各章节都有对应)
- 比如,对数几率回归/支持向量机/朴素贝叶斯/决策树/集成学习 等
- 深度学习
- 比如 cnn/rnn/attention 等模型
源码解析
1 | #!/usr/bin/env python3 |
如何提高模型性能
- 数据预处理
- 特征工程
- 机器学习算法
- 模型集成
