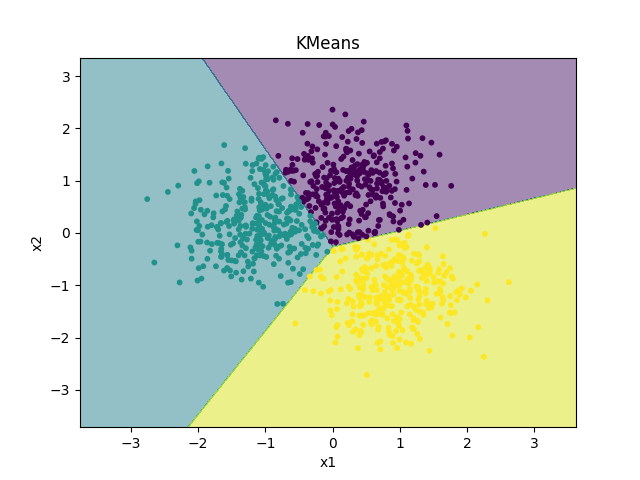
k-均值聚类
n 个样本分到 k 个不同的类或簇,每个样本到其所属类的中心的距离最小。
每个样本只能属于一个类,所有 k-均值聚类 是 硬聚类。
模型
- k < n
策略
- 距离: 欧式距离
- 损失函数:样本与所属类的中心的距离总保
- NP 困难问题
算法
目标函数极小化
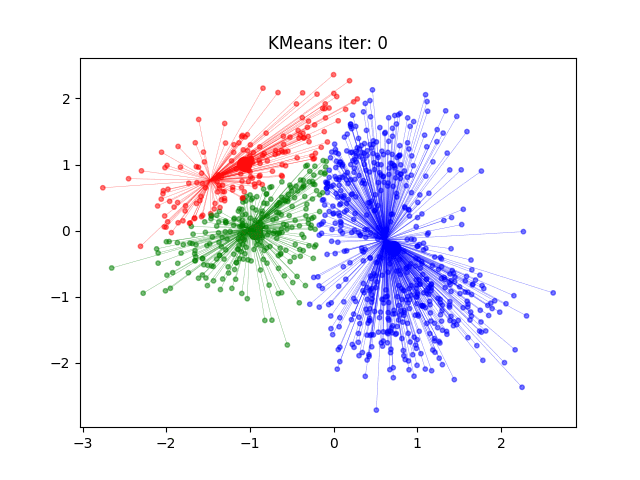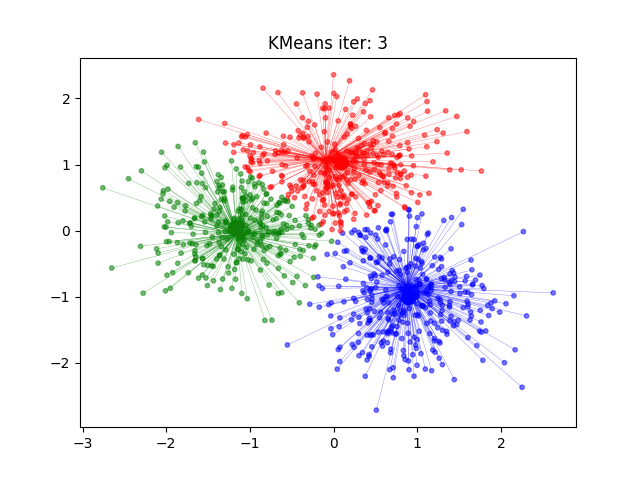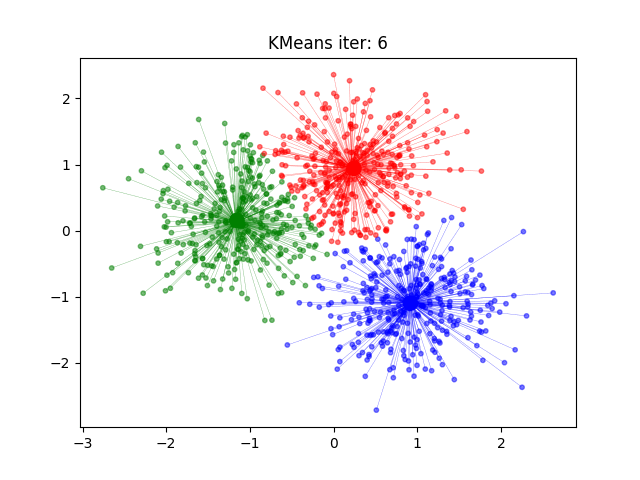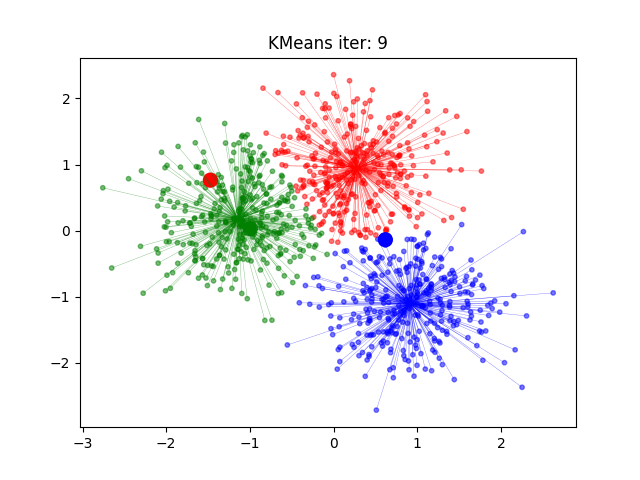
- 初始化,随机取 $ k $ 个样本做中心
- 对样本进行聚类,计算样本到类中心距离,每个样本指派到与其最近的中心的类
- 计算新的类中心。对聚类结果计算样本的均值,做为新的类中心
- 如果迭代收敛或符合停止条件,输出。否则,令 $ t = t + 1 $ ,返回 2
1 | def fit(self, X): |